
Introduction
Internet technologies have evolved and modern distributed systems employ several techniques to function effectively and efficiently. These systems and operational techniques are covered within this report, including the following topics; responsiveness, scalability, synchronisation, fault tolerance and availability. Current web based databases are also considered and finally an elastic name server service and controller is designed with a range of relevant technologies explored and evaluated.
Web 2.0
Kutemperor (2015, p. 8) states that “Information is todays currency” and can help drive business intelligence. Users are demanding more from the technology they utilise and the Internet is no exception. Worldwide we now generate huge amounts of data daily also known as Big Data (BD), be it vast scientific data sets, semi-structured or unstructured socially generated content. For instance, BGI in Shenzan, China generates 6 terabytes of scientific data daily (Marx, 2013, p. 258) and Twitter a popular social media platform over 1.5 terabytes (Murthy & Bowman, 2014). With content becoming bigger and more varied, storage and transport of this data requires consideration.
Cloud Computing
Cloud based computing is a networked group of servers based upon virtualisation technology for on demand resources as a service in strategic geographical locations (Montero, et al., 2011, p. 750).
Several companies now offer cloud based services such as; Amazon, IBM and Microsoft. Cloud based computing removes the need for localised hardware and allows for collaboration between required parties. In a case study of European Bioinformatics Institute by Marx (2013, p. 259), its noted that if they used on site equipment, one of the biggest challenges would be transferring the data to another party for analysis. Traditionally sent via post on hard disk drives; if this was to be downloaded by others then the internet bandwidth capacity required would be extremely costly to maintain. By using a cloud based solution this is eliminated allowing data analysis to be done centrally and putting the hardware responsibility solely in the hands of the cloud provider.
Cloud computing can also be of benefit cost wise employing elastic computing technology, expanding or contracting provisioned system resources or virtual worker nodes depending on the work load demand (Montero, et al., 2011, p. 752). This means you only pay for what you need when you need it, rather than purchasing physical equipment with set specifications (Povedano-Molina, et al., 2013, p. 2041). If savings can be made in, resources, transmission and storage focus can be moved to analysis.
Big Data
Anyone looking to leverage BD for numerous reasons, including but not limited to; sales and trends, process analysis or research, can use a variety of techniques including hardware based solutions be it small scale single node or larger scale multiple nodes. But, because this can be costly and difficult to manage, users are looking for alternatives in the cloud to either supplement existing hardware or to outsource completely (Marx, 2013, p. 259).
Big Data presents challenges for analysis, with structured data only making up 20% of modern data with the remaining 80% unstructured. Typical relational database models simply cannot handle the volume and variety of data to be analysed (Kutemperor, 2015, p. 8). Systems need to be scalable to handle this, Relational Database Management Systems (RDMS) scale well upwards whilst BD systems scale outwards; meaning that with an RDMS you can add more memory or storage etc. but it will always hit a limit. Software like Map Reduce has been introduced to resolve this using distributed systems, typically using many “nodes” to process and store data in parallel. Map-reduce has become widely used in data-intensive analysis in the cloud due to its fault tolerance and scalability (Vera-Baquero, et al., 2015, p. 221).
Because distributed nodes work individually on their assigned task to make up a whole complete system they may store only a portion of the overall dataset, these systems need to be fault tolerant and provide survivability. Some solutions like Riak focus on redundancy, availability and data replication, meaning that if one node goes down the data is still available elsewhere for processing. If this occurs the system will automatically be able to detect and react accordingly, allowing for smooth continuous operation and achieve a high level of availability without user intervention. The capability to recover from these states requires synchronisation between the nodes which can be geographically distributed for normal processing operation and redundancy (Deng, et al., 2008, p. 21).
Solutions like Hadoop focus more on data availability and responsiveness pertaining to result retrieval turnaround time and this provides users with analytic results faster which can be integrated into business or research planning at the earliest opportunity providing maximum benefit and value (Murthy & Bowman, 2014, p. 9).
Web Based Databases
Sticking to the adage “Information is today’s currency” (Kutemperor, 2015, p. 8) it is important to understand the landscape of database technologies. Databases are designed to solve real-life problems; the traditional RDBMS has been centered around query flexibility rather than flexible schemas. However, this is changing. Relational databases using the Structured Query Language (SQL) have been the industry de facto standard for years but new approaches have been developed and adopted under the guise of NoSQL including; Key-Value stores, Columnar, Document and Graph databases, with each presenting a solution to a problem and sometimes overlapping (Redmond & Wilson, 2012, pp. 1-7). A comparison table of SQL vs NoSQL sourced from MongoDB (MongoDB, 2016) is included as appendix item E.
With so many technologies their disposal, how do businesses choose the right tool for the job?
A lot will depend on the business objectives and the type of service to be offered. Redmond & Wilson (2012, pp. 1-3) suggest that six design issues should be considered
- The type of data store
- Driving force
- Communication methods
- Capabilities and constraints
- Performance
- Scalability
When looking at distributed databases there are also three factors to consider, known as the CAP theorem:
- Consistency
- Atomic writes – all subsequent reads provide the newest value
- Availability
- Returns a value if a server is running
- Partition
Tolerance
- Distributed over many nodes
A distributed database can either be partition tolerant and available, or partition tolerant and consistent, but not all three. (Murthy & Bowman, 2014, p. 3).
For smaller business models and even medium enterprises looking for everyday use and ecommerce the relational database model will normally be sufficient, providing cost effective and industry proven solutions such as MySQL and PostgreSQL. The relational model excels at providing flexible data queries along with consistent data; provided the data to be stored is reasonably homogeneous and conforms to a structured schema. However, the relational model does not scale out horizontally and does not deal well with unstructured heterogeneous data (Murthy & Bowman, 2014, pp. 3-4). NoSQL databases have been designed to handle these situations and a few are outlined next.
NoSQL Technologies
Facebook, Twitter and Ebay to name but a few have all employed the use of a columnar data store named HBase which is proficient when it comes to consistency and has a wide range of applications. It also includes features such as garbage collection, compression, versioning, in-memory tables with interaction provided via Java (Apache HBase Team, 2016). It is being used by companies for big data analytics over and above many gigabytes in size. Storing data as JSON in multidimensional maps, figure 1 and compared with other databases, Hbase will often outpace the competition when performing large queries (Redmond & Wilson, 2012).

Large business models employing web based data centers such as Amazon or Twitter have turned to key-value solutions such as Riak, which in part due to its distributed scalable nature provides fault tolerance and availability. However, lacks data consistency not guaranteeing the latest value (Basho Technologies Inc, 2016). Keys (maps), figure 2, can store values in plain text, XML, JSON, images and even video clips. Riak offers a solution for services that require the ability to serve a great number of requests with extremely low latency via a HTTP REST interface. The drawbacks of some key-value stores can be the inability to link values between tables and perform ad hoc queries (Redmond & Wilson, 2012).

Dealing with huge volumes of data can be a challenge. One system that deals well with this is a scalable database MongoDB. With its name originating from humongous, MongoDB is a highly available document orientated database that stores data in JSON strings (figure 3) and supports ad hoc queries (Redmond & Wilson, 2012, pp. 135-136).
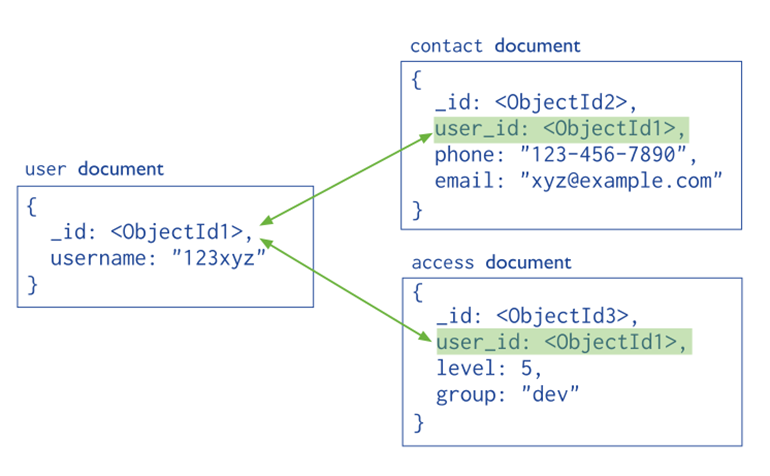
JSON or XML, as shown in figure 4, provides the added advantage that many APIs like Google’s graphing API (Google, 2016), accept this input and can therefore be easily exported to different analytics platforms.

Database Technologies Summery
It is clear from the discussion of options presented that there is not a one size fits all database and projects may require one or more of the different solutions to provide the best service for the customer. Decisions must be made over constancy or availability and which is more important and, additionally, one must remain mindful of how the data is to be queried, exported and or analysed.
Load Balancer Project
With distributed systems comes the requirement of knowing where to direct a client. If all clients were to access a single node it would most likely cause network congestion and or performance issues for the node in question. This could lead to overloading the service causing it to crash.
For this project a load balancer aimed at an elastic computing service will be designed and implemented, selecting appropriate tools and techniques as required with decisions made based upon the research performed in this report.
Communication Flow
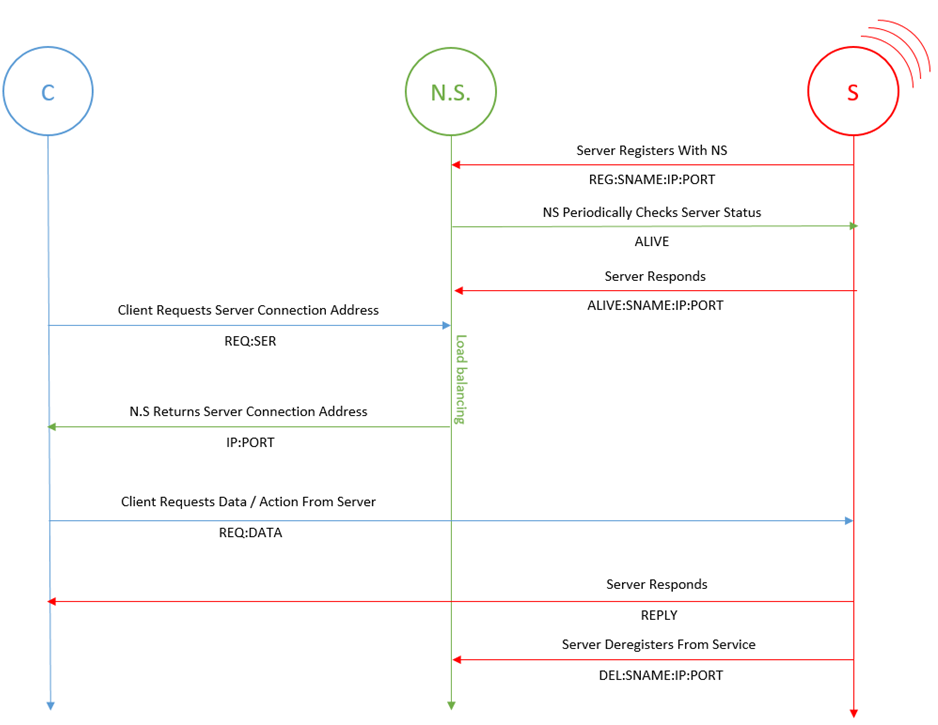
Detailed below in figure 5 is the proposed communication flow between Name Server (NS), the servers (S) providing the actual service and the client (C) requesting the service.
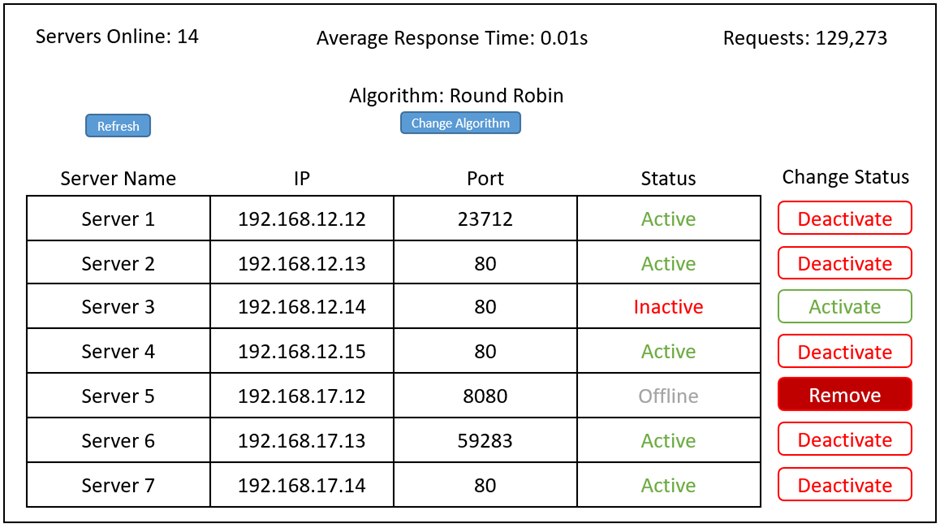
It is proposed that the nameserver will be managed from a web portal, the service controller and a brief mock-up has been created figure 6.
Languages
The language chosen for development of the nameserver is C.
C is a low-level language providing access to system calls, direct memory management and fast performance. C can often be the largest code set running on a machine as programmes complied in C will frequently be smaller in size than their counterparts and outpace them in performance (Anon., 2011) (Devietti, et al., 2008) (Nanz & Furia, 2015). Given that client–request turnaround time is paramount in the service execution, C is an appropriate choice. However, servers could be written in any language providing socket capabilities and clients should be able to request the service IP:PORT from the nameserver regardless of base language.
| Name Server Requirements | Client Requirements |
| Respond to client REQ requests | Send REQ request |
| Resolve server REG requests | Receive reply from NS |
| Resolve server REM removal | Identify IP / Port supplied |
| Resolve controller algorithm ALG change | Connect to supplied credentials |
| Resolve server online status changes | Receive reply from connected service |
| Record to datafile for transition between sessions | |
| Load from data file upon service start | |
| Provide JSON output for data storage | |
| Generate and supply JSON on HTTP request |
Nameserver Data Structures
To provide servers to clients the NS needs to store registered servers in memory. Several methods are looked at below covering structs, arrays, linked lists and binary trees.
Structs
Structs allow for custom data types to be defined within C, like objects within Object Oriented Programming but without any implementation or methods, a container for one or more data types or custom structs (Toutorials Point, n.d.). The Data types selected are designed to hold a complete server with unsigned long integers for statistical recording in the event values increase above 32767 for a signed integer (Tutorials Point2, n.d.) (ARMmbed, n.d.).

Arrays
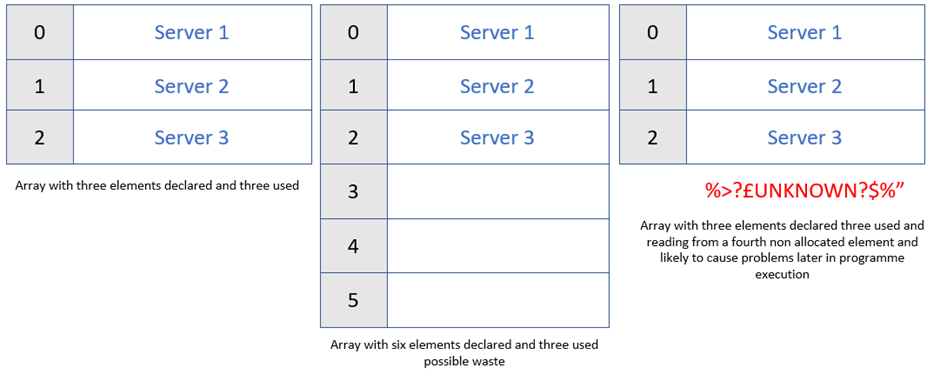
Arrays have the advantage of being very fast to access via index and can be the base for other data structures but they also have some disadvantages. One being that the number of items to be stored needs to be known ahead of time; when array is declared, the memory is allocated. Declaring too much space is wasteful and too little provides the possibility of writing to memory that doesn’t belong to the array, causing unexpected behaviour. Reading beyond the array is also a problem which could return unknown results, as depicted in figure 9. Expanding and contracting arrays can be inefficient especially working with large data sets. Either a new array is created with a new memory allocation copying the elements between the two arrays or statically declare the array size and use a pointer variable to track the maximum stored value. (Geek, 2008) (Lamar, 2008).
Linked Lists
Linked lists use pointers to locations in memory to identify the next or, in some cases, the previous item within a list. Considering the struct below in figure 10, pointers can be identified for the next and previous items and a simplified example of the link list is presented in figure 11.


In the example given above, figure 11, the memory addresses are concurrent, but in operation this probably will not be the case. Linked lists are very capable of inserting or removing data in the middle of the list, unlike arrays. Take for instance the removal of server two from figure 9. Server 1 would just need to update the nextPtr value to 29 and Server three would update the prevPtr to 1, removing Server 2 from the linked list.
The insertion and deletion properties of linked lists are advantageous when large amounts of data insertion or removal are required. However, to access data in Server 3 the list would need to be searched and traversed from Server 1 all the way to Server 3, providing slower lookup than an indexed array going directly to position 3. (Geek, 2008) (Lamar, 2008) (Tutorials Point, n.d.).
Binary Tree
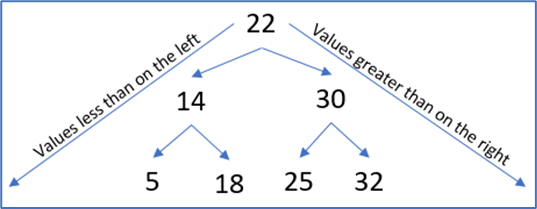
Binary trees are efficient for searching and sorting data. Binary trees function in a similar fashion to linked lists with pointers to memory locations. Beginning with a root node, subsequent entries can be added creating a leaf, if entries are added below these they become a branch node and the child becomes a leaf with lower values stored to the left and higher to the right as shown in figure 12. Common functions can include data insertion, deletion and traversal with process difficulty dependant on the size of the tree, if it is balanced and if sub nodes are leaf or branch nodes (Allain, n.d.) (Learn-C.org, n.d.).
Data Storage and Server Persistence
In regards to data storage and transmission, further tests have been performed related to storage sizes. The comparison below, figure 13, shows a file size of 102 servers in JSON versus 102 in XML, the XMLs “bloated” descriptors almost double the file size if there were 103 or 106 servers the difference quickly becomes apparent.
Both XML and JSON was minified to exclude white space.

JSON has therefore been chosen to represent the service data due to the smaller size compared with XML and backs the research performed in previous sections of this report. This data is written to a file to provide a load function within the NS so that upon restarting the service servers are not lost requiring re-registration.
By using JSON in this fashion it also eliminates resource requirements for running a parallel database solution.
Implementation
In this project the NS will be defined as handling a maximum of 100 servers and will store server structs within an array of 100 elements. A global integer variable will then be used to track the last element location avoiding memory corruption. Due to the scope of this implementation it is not envisaged that large numbers of server additions or deletions will take place or require insertion into the middle of the array and, as such, will be handled by copying elements between array positions when required and not utilise linked lists or binary trees.
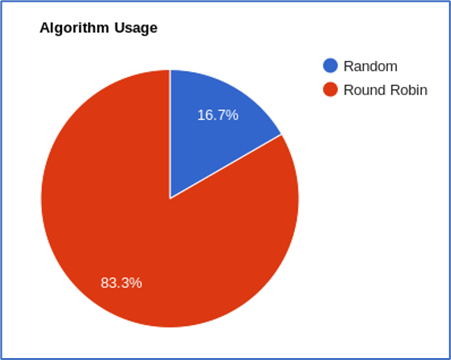
The completed NS code supplied in the appendix item A is lengthy. However, the NS works registering and deregistering servers, suppling statistical data in the form of JSON and the main service of suppling a requested IP and port. The algorithm for server selection has two forms, round robin cycling through the server list one by one providing an unbiased split and a random function generating a random number for server selection.
Other algorithms have been considered for implementation such as weighted round robin, operating much like round robin but with servers allocated a weighting and some receiving a larger share of the workload. Least traffic was also considered, where the size of data transmitted is communicated to the service controller, possibly via IPC, providing servers with a larger capacity with more clients whilst still utilising servers with lower capacity (Cisco, 2005) (IBM, n.d.) (Mortensen, 2010). However, these algorithms are beyond the scope of this project and have not been implemented in the final solution.
To maintain high throughput, process forking using the fork() command will be used allowing the parent process to continue accepting new requests, whilst a child fulfils the request.
Development Environment
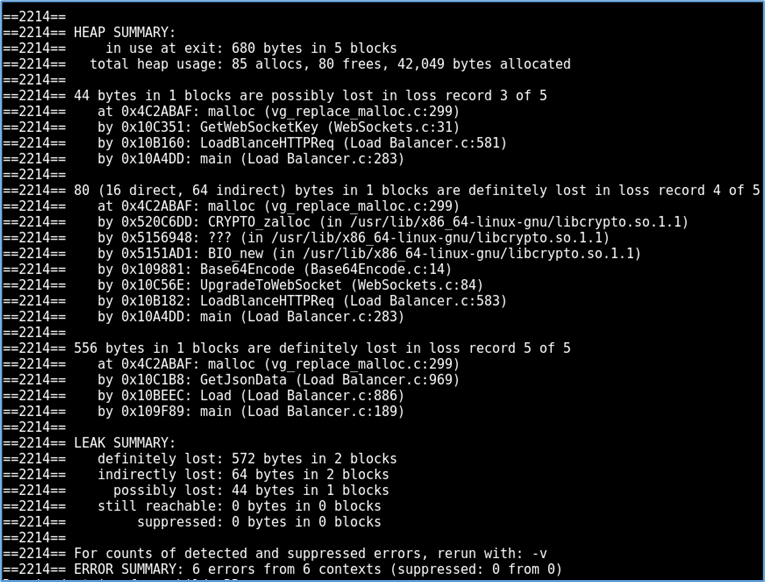
Eclipse has been used in the development of the NS providing syntax and common error checking. Eclipse also comes with the benefit of a debugger with breakpoints for inspecting code (Eclipse, n.d.). However, outputs from invalid memory operations can be challenging to decipher and the use of Valgrind (Valgrind, 2016) was undertaken to solve these; figure 14.
Service Controller
For the service controller two separate designs are proposed; a PHP solution and a HTML / JavaScript (JS) solution. A basic PHP solution is provided in appendix item C and a full completed HTML JS solution as appendix item B. A brief comparison of the two solutions is detailed below in figure 15.

Whilst both provide the required functionality for monitoring and updating the NS, the HTML JavaScript implementation delivers maintainability, specifically not requiring the use of additional resources required for running and maintaining an Apache, MySql and PHP solution. Although, with the HTML / JS controller, it is proposed that in the implemented solution additional files such as cascading style sheets are maintained externally on a dedicated web server to lower unnecessary requests allowing the NS it to fulfil its primary role.
These could alternatively be hardcoded inline within the served HTML page depending on size or a separate service could be created to handle web requests utilising Inter Process Communication (IPC) such as a pipe to communicate with the NS.
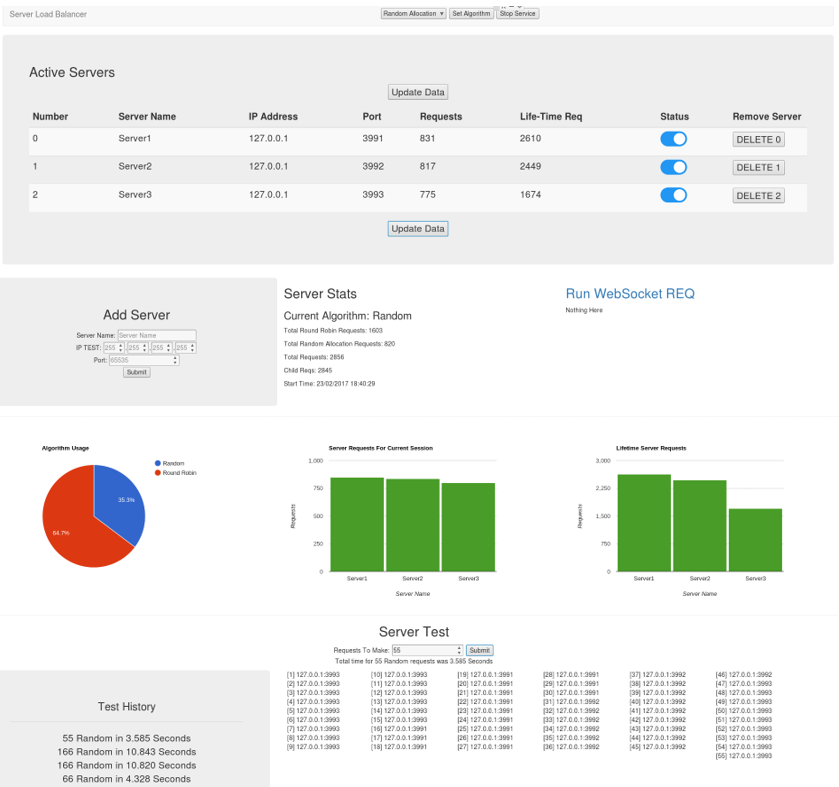
Within the service controller, figure 16, data is obtained via JSON generated dynamically by a child process and served back to the controller via a web-socket, this eliminates concurrency issues potentially arising from both the controller and the nameserver trying to read / write from the same data file simultaneously. Another solution, not implemented, involves the use of semaphores and could be used if the NS was to be split down into separate C services (Downey, 2015). However, a benefit of using HTML/JS comes from using client resources. Once the page is loaded servers could be monitored from a remote machine using local resources with the NS updated accordingly.
The service controller currently provides the ability to register new servers, delete existing servers, provide graphical and numeric statistical data, toggle server online status, change algorithm and perform REQ request tests. It is written entirely using HTML, CSS and JavaScript providing a lightweight solution independent of other running services. To provide this service upgraded WebSocket were introduced into the NS.
As an alternative to a web based solution, the service controller could be application or command line based. These options have not been chosen over the web based solution due to command line not being user friendly for all skill levels and an application based where a separate software installation is required to operate. A PHP, command line or application based controller would require little alteration to the NS code base, unlike JavaScript web sockets. However, once this is implemented it provides added security and utilises fewer direct NS resources.
WebSockets
To provide an upgraded HTML5 JS connection additional code has been required within the NS, whereas PHP can work with the standard sockets, the JS web-socket connection must be upgraded. The process for doing such is detailed below in figure 17 (Mozilla Developer Network, 2017).

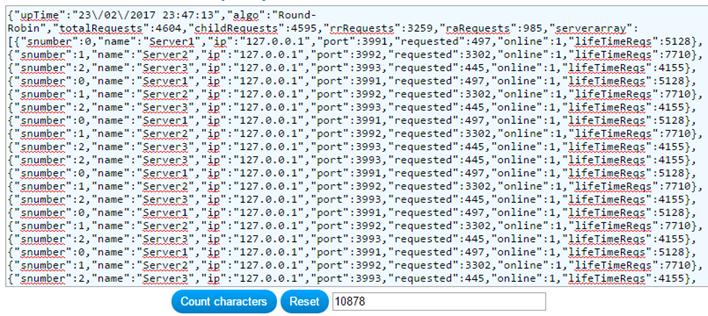
Rudimentary code has been written to support encoding outgoing WebSocket frames and decoding incoming frames based upon the pseudocode provided on Stack Overflow (2011). However, this is not a full implementation as strings over 65535 chars in length are not handled and only strings under 125 chars in length can be received from the client without fault. This is not seen as a problem in the current solution as a completed server array of 100 elements equates to approximately 10900 characters of saved JSON, demonstrated in figure 18, potentially offering service capabilities of around 5000-6000 active servers without JSON data transmission failure.
Google Charts
Additional benefits of a web based solution over command line or simple a simple application controller comes when utilising the JSON storage system to visually display statistical data generated by the NS using Google Charts. Natively accepting JSON arrays or easily adapting JS JSON Objects to be presented in a variety of customisable formats (Google, n.d.).
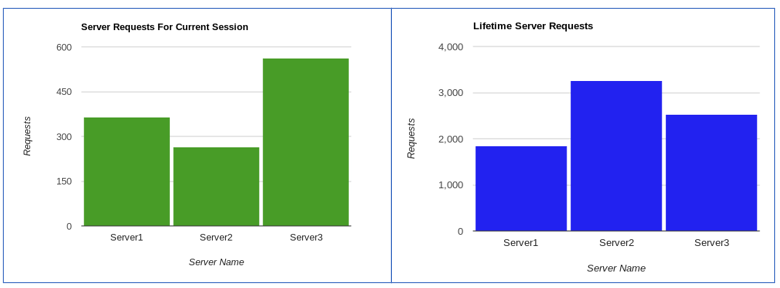
Due to this interoperability Google Charts has been implemented within the service controller to display current and historical data shown below in figures 19 and 20.
Solution Evaluation
The implemented solution operates as expected, providing a service to clients and servers alike. Two videos have been included as figures 21 and 22 presenting the final solution with feature demonstration.
Scalability has been addressed allowing servers to register and de-register as required as well as numeric throughput tracking with session state. Originally the child would use IPC to write to an allotted pipe, then catch the SIGCHILD signal generated by the child closing, within the parent. The parent process would then read any written data from the pipe. However this has been altered to the parent checking immediately after the fork() process due segmentation faults occurring during stress testing.
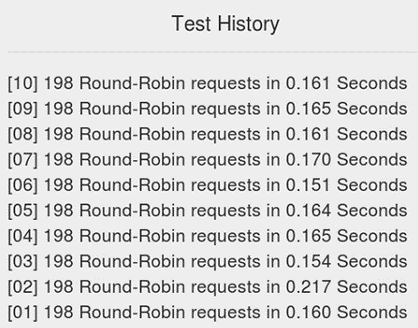
The NS responds to 198 REQ requests within an average time of 0.168 seconds, figure 21, providing a good responsiveness to clients. However, additional work is required to maintain availability. Currently the NS controller is unable to detect or communicate with the registered servers as they do not implement upgraded WebSockets. This alive check could be implemented directly into the NS but ideally would be handled separately within the HTML / JS controller.
The web based controller produced provides increased service visability over and above a simple console based application and given the ease to display JSON data visually, providing non technical users an interactive interface quickly on widely used tools. The web also has advantage over a full WPF application which has less portability and would require additional coding to achieve the same results.
Future works
The current solution could be improved by implementing the following;
- Secure server registration
- Provide a way to authenticate registering servers as genuine service providers
- Server WebSocket communication
- Allowing for service controller to check alive status of servers
- Additional load balancing algorithms
- Allows for improved distribution services
- E.g. Weighted Round Robin
- Service splitting
- Split the NS and basic webserver into two separate services
- Increase code maintainability
- Reduce load placed upon each service
- Use of IPC to update.
- Additional data logging
- Record host connection and requests within JSON logfile
- If REQ request received log supplied server
- Split the NS and basic webserver into two separate services
Conclusion
It is clear from the discussion of options presented, that in the world of Web 2.0 dealing with distributed systems there is not a one size fits all solution. Decisions must be made over constancy or availability and which is more important. Additionally, one must remain mindful of how the data is to be queried, exported and or analysed.
Further, for these distributed systems to operate effectively load balancing and control needs to be in place to maintain high availability or consistency and the research and exercises performed within this report provides firm insights into modern Web 2.0 definitions and scope alongside databases, data storage and the workings of distributed systems with their requirements.
References
Allain, A. (n.d) Binary Trees in C.
Available at: http://www.cprogramming.com/tutorial/c/lesson18.html
(Accessed: 18 December 2016).
Anon. (2011) The Tower of Babel — A
Comparison Programming Languages.
Available at: http://www.cprogramming.com/langs.html
(Accessed: 12 Novemeber 2016).
Apache HBase Team, (2016) Apache
HBase ™ Reference Guide.
Available at: http://hbase.apache.org/book.html#conceptual.view
(Accessed: 23 November 2016).
ARMmbed, (n.d). C Data Types.
Available at: https://developer.mbed.org/handbook/C-Data-Types
(Accessed: 2016 December 2016).
Basho Technologies Inc, (2016) Eventual
Consistency.
Available at: https://docs.basho.com/riak/kv/2.0.1/learn/concepts/eventual-consistency/#a-simple-example-of-eventual-consistency
(Accessed: 23 November 2016).
Basho Technologies, Inc., (2016). Data
Types.
Available at: https://docs.basho.com/riak/kv/2.0.1/learn/concepts/crdts/
(Accessed: 23 November 2016).
Cisco, (2005) Understanding CSM Load
Balancing Algorithms.
Available at: http://www.cisco.com/c/en/us/support/docs/interfaces-modules/content-switching-module/28580-lb-algorithms.html
(Accessed: 4 February 2017).
Deng, Y., Wang, F., Helian, N., Wu, S., Liao, C., (2008) Dynamic and scalable storage management architecture for grid oriented storage devices. Parallel Computing, 34(1), pp. 17-31.
Devietti, J., Blundell, C., Martin, M. & Zdancewic, S., (2008). Hardbound: architectural support for spatial safety of the C programming language. ACM SIGARCH Computer Architecture News, 36(1), pp. 103-114.
Downey, A. B., (2015) Think OS, A Brief
Introduction to Operating Systems.
Available at: http://greenteapress.com/thinkos/thinkos.pdf
(Accessed: 26 February 2017).
Eclipse, (n.d) Eclipse IDE for C/C++
Developers.
Available at: http://www.eclipse.org/downloads/packages/eclipse-ide-cc-developers/keplersr2
(Accessed: 14 October 2016).
Geek, (2008) Array vs Linked List.
Intro, Pros & Cons, Usage, etc..
Available at: http://geekexplains.blogspot.co.uk/2008/05/array-vs-linked-list-advantages-and.html
(Accessed: 18 December 2016).
Google, (2016) Populating Data Using
Server-Side Code.
Available at: https://developers.google.com/chart/interactive/docs/php_example
(Accessed: 23 November 2016).
Google, (n.d) Google Charts.
Available at: https://developers.google.com/chart/
(Accessed: 20 February 2017).
IBM, (n.d) Algorithms for making
load-balancing decisions.
Available at: http://www.ibm.com/support/knowledgecenter/SS9H2Y_7.2.0/com.ibm.dp.doc/lbg_algorithms.html (Accessed:
4 February 2017).
JSON, (n.d) JSON Example.
Available at: http://json.org/example.html
(Accessed: 23 Nvemeber 2016).
Kutemperor, N., (2015) Price/Performance Considerations in Building Data. Business Intelligence Journal, 20(2), pp. 8-13.
Lamar, (2008) When to use a linked list
over an array/array list?.
Available at: http://stackoverflow.com/questions/393556/when-to-use-a-linked-list-over-an-array-array-list
(Accessed: 18 Decemeber 2016).
Learn-C.org, (n.d) Binary Trees.
Available at: http://www.learn-c.org/en/Binary_trees
(Accessed: 18 December 2016).
Letter Count, (n.d) LetterCount.com.
Available at: http://www.lettercount.com/
(Accessed: 02 20 2017).
Marx, V., (2013) The big challenges of big data. Nature, 498(7453), pp. 255-260.
MongoDB, (2016) Data Modeling Introduction.
Available at: https://docs.mongodb.com/manual/core/data-modeling-introduction/
(Accessed: 23 November 2016).
MongoDB, (2016) NoSQL Databases Explained.
Available at: https://www.mongodb.com/nosql-explained
(Accessed: 15 November 2016).
Montero, R. S., Moreno-Vozmediano, R. & Llorente, I. M., (2011) An elasticity model for High Throughput Computing clusters. Journal of Parallel and Distributed Computing, 71(6), pp. 750-757.
Mortensen, J., (2010) What kind of load balancing
algorithms are there.
Available at: http://serverfault.com/questions/112292/what-kind-of-load-balancing-algorithms-are-there/112313
(Accessed: 4 February 2017).
Mozilla Developer Network, (2017) Writing
WebSocket servers.
Available at: https://developer.mozilla.org/en-US/docs/Web/API/WebSockets_API/Writing_WebSocket_servers
(Accessed: 22 January 2017).
Murthy, D. & Bowman, S. A., (2014) Big Data solutions on a small scale: Evaluating accessible high-performance computing for social research. Big Data & Society, 1(2).
Nanz, S. & Furia, C. A., (2015) A comparative study of programming languages in Rosetta Code. In Software Engineering (ICSE), 2015 IEEE/ACM 37th IEEE International Conference, Volume 1, pp. 778-788.
Povedano-Molina, J., Lopez-Vega, J.M., Lopez-Soler, J.M., Corradi, A. and Foschini, L., (2013) DARGOS: A highly adaptable and scalable monitoring architecture for multi-tenant clouds. Future Generation Computer Systems, 29(8), pp. 2041-2056.
Redmond, E. & Wilson, J. R., (2012) Seven Databases in Seven Weeks – A Guide to Modern Databases and the NoSQL Movement. s.l.:Pragmatic Bookshelf.
StackOverflow Community, (2011) How can I
send and receive WebSocket messages on the server side?.
Available at: http://stackoverflow.com/questions/8125507/how-can-i-send-and-receive-websocket-messages-on-the-server-side
(Accessed: 24 January 2017).
Tutorials Point, (n.d). Data Structure and
Algorithms – Linked List.
Available at: https://www.tutorialspoint.com/data_structures_algorithms/linked_list_algorithms.htm
(Accessed: 18 December 2016).
Tutorials Point, (n.d) C – Structures.
Available at: https://www.tutorialspoint.com/cprogramming/c_structures.htm
(Accessed: 18 December 2016).
Tutorials Point, (n.d) C – Data Types.
Available at: https://www.tutorialspoint.com/cprogramming/c_data_types.htm
(Accessed: 18 December 2016).
Valgrind, (2016) Valgrind.
Available at: http://valgrind.org/
(Accessed: 18 02 2017).
Vera-Baquero, A., Colomo Palacios, R., Stantchev, V. & Molloy, O., (2015) Leveraging big-data for business process analytics. The Learning Organization, 22(4), pp. 215-228.